
 La idea nuclear de este posteo es que, conociendo los algoritmos que intervienen en las plataformas de redes sociales, así como los que procesan la Bigdata, la comprensión de los fenómenos sociales mejora.
La idea nuclear de este posteo es que, conociendo los algoritmos que intervienen en las plataformas de redes sociales, así como los que procesan la Bigdata, la comprensión de los fenómenos sociales mejora.
Ahora bien. ¿Qué es un algoritmo? En principio es un conjunto de reglas concretas y secuenciadas que permiten que se produzca un comportamiento predefinido con un objetivo mensurable.
En términos generales cosas como sumar, fabricar una escoba, abrir una puerta, contestar un email o usar un artefacto electrónico suponen la existencia de un flujo de reglas secuenciadas para que se produzca ese resultado buscado (lease resolver un problema).
Un manual de uso es el ejemplo típico, pero puede resultarnos demasiado lineal: de hecho gracias a la evolución el cerebelo, un órgano que se ubica detrás del cerebro, tiene engramas funcionales donde existen registros precargados de modos de actuar que regulan la mayoría de nuestros actos vitales, sobretodo los que hacemos cotidianamente sin pensar. El cerebelo sería como la máquina de algoritmos de la mente.
¿Porque nos sirve el cerebelo como metáfora? Porque debe lidiar con muchísimos datos, debe navegar el exceso de información que le proveen los sentidos y las diferentes operaciones que realiza el cerebro. Como tuvieron que hacer Yahoo y Google en el principio de los tiempos, en los que se enfrentaron a una Internet que se parecía al caos del clima.
Casi todos nosotros tenemos nuestro meteorólogo de barrio que es mejor para predecir si hay que salir o no con paraguas, pero ahora los programas algorítmicos de predicción del tiempo utilizan más de un siglo de datos para determinar los patrones de clima con meses de antelación con una precisión del 74% , casi el doble de lo que métodos convencionales logran actualmente. La pregunte es: las sociedades se parecen en algo al clima?
No lo podemos decir, pero como las hormigas si. Por lo menos eso dicen en Icosystem, una empresa que aplica modelado basado en agentes. Pepsi utilizó su servicio para ayudarles a entender cómo los consumidores se mueven a través de un supermercado y lo hacen como hormigas.
Antecedentes
 El origen de estas ideas lo vimos en la astronomía griega, pero tambien lo podríamos asociar a los primeros estudios epidemiológicos, cuando la peste bubónica creaba larguísimas listas de mortalidad (Bills of Mortality) en las parroquias de Londres que fueron el deleite de Graunt un vendedor de telas del siglo XVII.
El origen de estas ideas lo vimos en la astronomía griega, pero tambien lo podríamos asociar a los primeros estudios epidemiológicos, cuando la peste bubónica creaba larguísimas listas de mortalidad (Bills of Mortality) en las parroquias de Londres que fueron el deleite de Graunt un vendedor de telas del siglo XVII.
El comercio de tejidos hoy es uno de los mas estadísticamente predecibles aun en países inestables como Argentina, he conocido personalmente fabricantes que han errado en menos de diez el cálculo de jeens a producir por años. En 1662 publicó un libro con el intrigante nombre de «Natural and Political Observations …»
En extensas matrices que hoy cargaríamos en un excel o programa equivalente listaba enfermedades como letargo, enfermedad del sueño, dolor, sífilis o peste bubónica y otras como «El mal del Rey ‘,una inflamación de los ganglios linfáticos en el cuello, que sólo podía ser curada por el toque de un monarca y que Graunt desestimó acertadamente, ya que hoy sabemos que era una forma de tuberculosis.
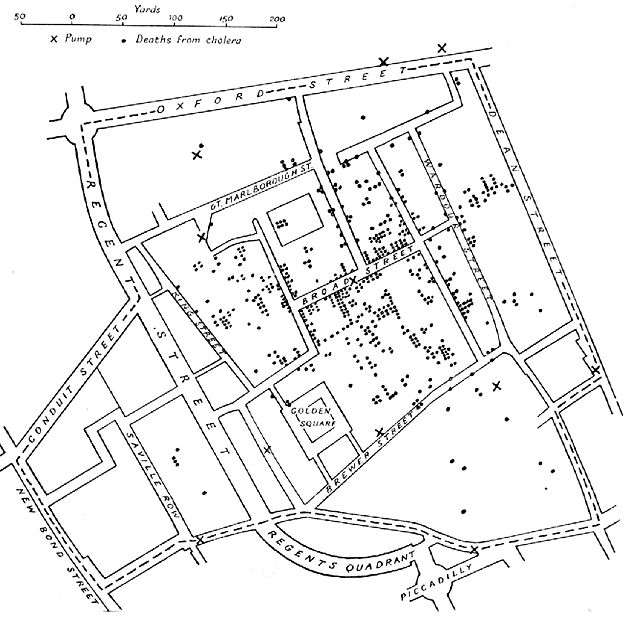 Dos siglos después el enfoque epidemiológico fue usado por John Snow que descubrió que (confeccionando un mapa de Londres donde centenares de personas habían muerto en apenas una semana) que todas las muertes habían ocurrido en el área de Golden Square donde la compañía de agua privada que suministraba al vecindario extraía el agua de una sección del Támesis especialmente contaminado. Cuando se cambió el agua y comenzó a extraerse río arriba la epidemia de cólera se redujo significativamente.
Dos siglos después el enfoque epidemiológico fue usado por John Snow que descubrió que (confeccionando un mapa de Londres donde centenares de personas habían muerto en apenas una semana) que todas las muertes habían ocurrido en el área de Golden Square donde la compañía de agua privada que suministraba al vecindario extraía el agua de una sección del Támesis especialmente contaminado. Cuando se cambió el agua y comenzó a extraerse río arriba la epidemia de cólera se redujo significativamente.
El algoritmo de Snow era simple: seleccionaba los casos confirmados de cólera, les atribuía una geoposición, cargaba esos datos en un mapa según fechados y con eso obtenía visualizaciones en las que reconoció un patrón que permitió tomar medidas políticas.
Pero en matemáticas los algoritmos son una cosa seria y que pueden producir enormes beneficios a sus creadores. Google mismo no es mas que un complejo algoritmo que transforma los datos de un problema (la búsqueda) en los datos de una solución (los resultados).
Lo que no queremos ver
El miembro de MoveOn.org ELi Pariser bautizó esta idea como «burbuja filtrada» (me gusta mas que la traducción «filtro burbuja»): el resultado es que recibiremos principalmente noticias agradables, familiares y que confirmen nuestras creencias. Como estos filtros son invisibles, no vamos a saber lo que se nos oculta.
Los algoritmos determinarán a que estaremos expuestos en el futuro, dejando menos espacio para la innovación y el intercambio de ideas con personas de intereses diferentes y eso es tambien verdad para sitios como OkCupid.
La idea de Burbuja Filtrada revela cómo esta personalización algorítmica podría socavar el propósito original de la Internet como una plataforma abierta para la difusión de ideas.
Pero hay otros usos del filtrado de grandes datos, por ejemplo en predicción de delito se estima que el algoritmo lo reduce un 20 30 % mediante el patrullaje selectivo de zonas de riesgo.
Las discográficas utilizan software llamado Music X-Ray para juzgar la si una nueva pista es probable que sea un éxito o un fracaso, otra empresa, Epagogix, utiliza un proceso similar al evaluar guiones para los estudios de Hollywood.
De alguna manera todo el comportamiento humano, desde la medicina a la publicidad está siendo atravesada por esta lógica de procesos que no solo reconocen patrones en bancos de datos, sino que aprenden de sus propios resultados.
Las dos lógicas que animan estos posteos (Bigdata y análisis de redes sociales) terminan implicados como veremos.
Machine Learning
Pero no solo la búsqueda en sí. En diciembre de 2009, Google comenzó la personalización de sus resultados de búsqueda para todos los usuarios, lo que se está llevando a cabo en todos los sitios web más importantes como Facebook, Twitter o empresas basadas en información como Apple o Microsoft que cierran su negocio basicamente con la venta de información a sus anunciantes. El resultado es que cada vez vamos a ver nuestro propio universo informacional depurado por algoritmos.
De lo que estamos hablando es de cierta vanda de moebius en la que somos un poco maquinas, pero los artefactos son casihumanos. Primero fueron la inteligencia artificial y las redes neuronales, pero el nuevo paso es el Machine Learning (ML), un tipo de análisis de datos que permite a las computadoras sacar conclusiones a partir de grandes conjuntos de datos, mediante la construcción de modelos predictivos y el muestreo repetido de datos.
Machine Learning es un proceso iterativo, por lo que, cuanto más datos que el sistema consigue, mejores predicciones puede hacer. Sin embargo el truco consiste en encontrar que cantidad de datos es suficiente.
Todos los algoritmos de ML consisten en las siguientes tres cosas:
- Un conjunto de modelos posibles (ej. cantinas casi infinitas en una ciudad) para detectar la mejor cantina.
- Una manera de probar si un modelo es bueno (ir a comer a cada una) o mejor que otro.
- Una forma inteligente de encontrar ese buen modelo con sólo unos pocos pasos (menú, el edificio, el barrio, la cantidad de comensales, etc)
Debido a que por lo general requiere una gran cantidad de potencia de cálculo, su uso se ha restringido a la comunidad académica hasta hace muy poco aunque gracias a la computación en nube Machine Learning en más asequible: Microsoft lanzó su servicio de Machine Learning comercial en febrero de este año.
Por ejemplo Fujitsu ha construido un sistema que utiliza Azure para ayudar a los agricultores japoneses a predecir mejor momento para inseminar vacas lecheras, mejorando el rendimientos de cada animal.
Cada vaca está equipada con un sensor en una de sus piernas que registra cuántos pasos da por día: los datos del sensor se transmiten a Azure, que puede identificar las vacas en celo.
El método clásico para detectar una vaca inseminable acierta en un 33 %, pero el procedimiento ML puede alcanzar hasta un 95 %.
Ganadores que se quedan con los talentos
Mientras el mundo academico discurre estos asuntos, los artículos sobre las desigualdades en la financiación y las nuevas formas de financiar laboratorios han conseguido recientemente una gran cantidad de atención en Twtter.
Muchos investigadores han estado compartiendo ahí un artículo que dice qye la financiación de la ciencia no siempre va a los más meritorios.
El artículo, escrito por la sociólogo Yu Xie en la Universidad de Michigan, señala que la ciencia ahora se asemeja a un sistema de «el ganador se queda con todo» que otorga una parte desproporcionada de los recursos a una minoría de los investigadores e instituciones. Xie escribió que los científicos son cada vez menos juzgados por la calidad de su investigación, y mas por sus números: publicaciones, citaciones, salarios, subsidios y el tamaño de sus equipos de investigación.
Timothy O’Leary, un neurocientífico de la Universidad de Brandeis en Waltham, Massachusetts, tuiteó hace poco que los Postdocs están teniendo conversaciones sobre cómo moverse hacia arriba de la pirámide científica o cuando salirse a tiempo.
Allison Stelling, director de extensión para la ingeniería y la ciencia de los materiales mecánica en la Universidad de Duke, Carolina del Norte, dijo en Twitter que los actuales sistemas subestiman a los científicos: tienden a ver a los científicos como un gasto, no el corazón y el alma de la investigación. En su opinión, la financiación científica es demasiado escasa y concentrada en un pequeño numero de «ganadores».
Los algoritmos están siendo muy eficientes, pero no podemos quedarnos en esa mirada ingenua: las implicaciones respecto a nuestra capacidad de dejar huella en la realidad está seriamente cuestionada, aun respecto a los grandes popes de la ciencia. Un articulo reciente muestra que los expertos son muy propensos a estar equivocados y ademas que, dejados a una evolución silvestre, unos pocos se quedarán con todo.
Para el que se tome estos asuntos en serio los problemas que hay adelante son fascinantes.